# Continuous Learning (Beta)
**Continuous learning (CL)** is a major feature, enhancing AI models through user feedback. Following sufficient number of corrections to the extracted data in the Supervision view, the model undergoes automatic retraining. The resulting new model is exclusive to the user and is expected to exhibit improved accuracy, particularly on the documents for which corrections were submitted.
{% hint style="info" %}
**Accuracy** is a measure showing the correctness of the extracted data. It is usually expressed as a percentage. If the accuracy score is high, it indicates a minimal error - extracted data should be true to the information in the original documents.
{% endhint %}
Continuous Learning feature aims to improve the accuracy of matching extracted text (e.g. "Michael") to the correct data field (e.g. "First name"). It is not able to increase the accuracy of the extracted text itself though. The quality of the read data is the responsibility of the OCR - a functionality which scans and translates the document from image to text.
> **For example**, if the original text in document says "Michael" and Alphamoon's OCR will read it as "Mihael", using CL feature won't change the extracted text value.
### How to use the Continuous Learning feature in Alphamoon
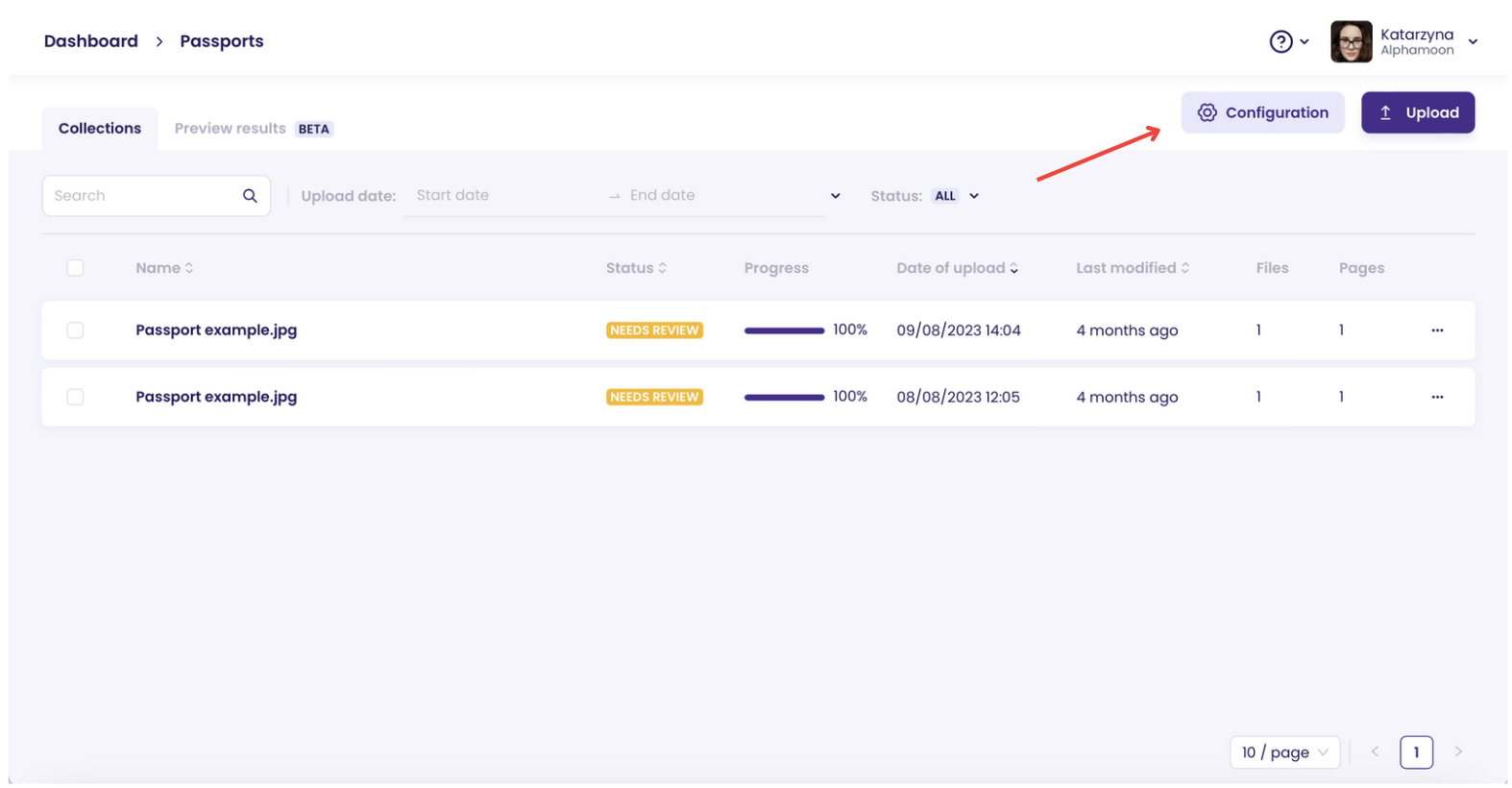
After you create your process and upload your documents, click the “**Configuration**” button in the Queue view.
Enter the Configuration
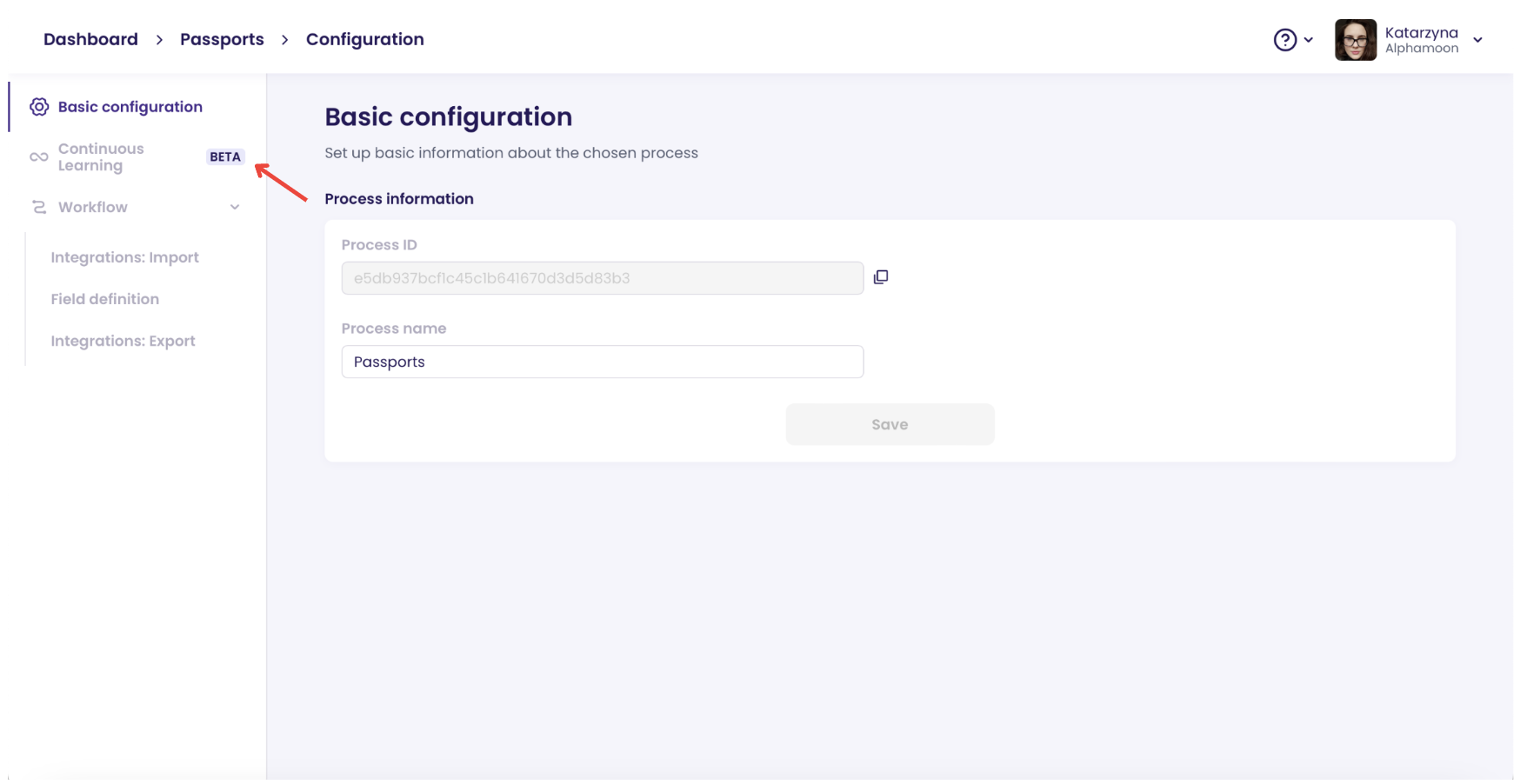
You will see the dashboard, where you can enter the “**Continuous Learning**” tab.
Open the Continuous Learning tab
Once you open the tab you can enable the Continuous Learning feature:
Enable the Continuous Learning feature
You can decide whether the model will improve automatically based on your data (in other words - collections you add) or select the "**Off**" option to disable the automatic scheduling.
To train the model on your own simply click the "**Train now**" button.
{% hint style="info" %}
Note that Continuous Learning takes into account corrections from the documents with the "Accepted" status. You can read more about the review process [here](https://alphamoon.gitbook.io/documentation/~/changes/E5WHATIwrsF0u91xTwvD/user-guide-how-tos/supervision/how-to-edit-the-value-of-the-extraction).
{% endhint %}
{% hint style="info" %}
We recommend **data-based** training if you want new models to appear automatically over time.\
\
**Manual training** (using the "**Train now**" button), on the other hand, is the best option for users who want more control over the training process. In this case, you only train the model if you want to.
{% endhint %}
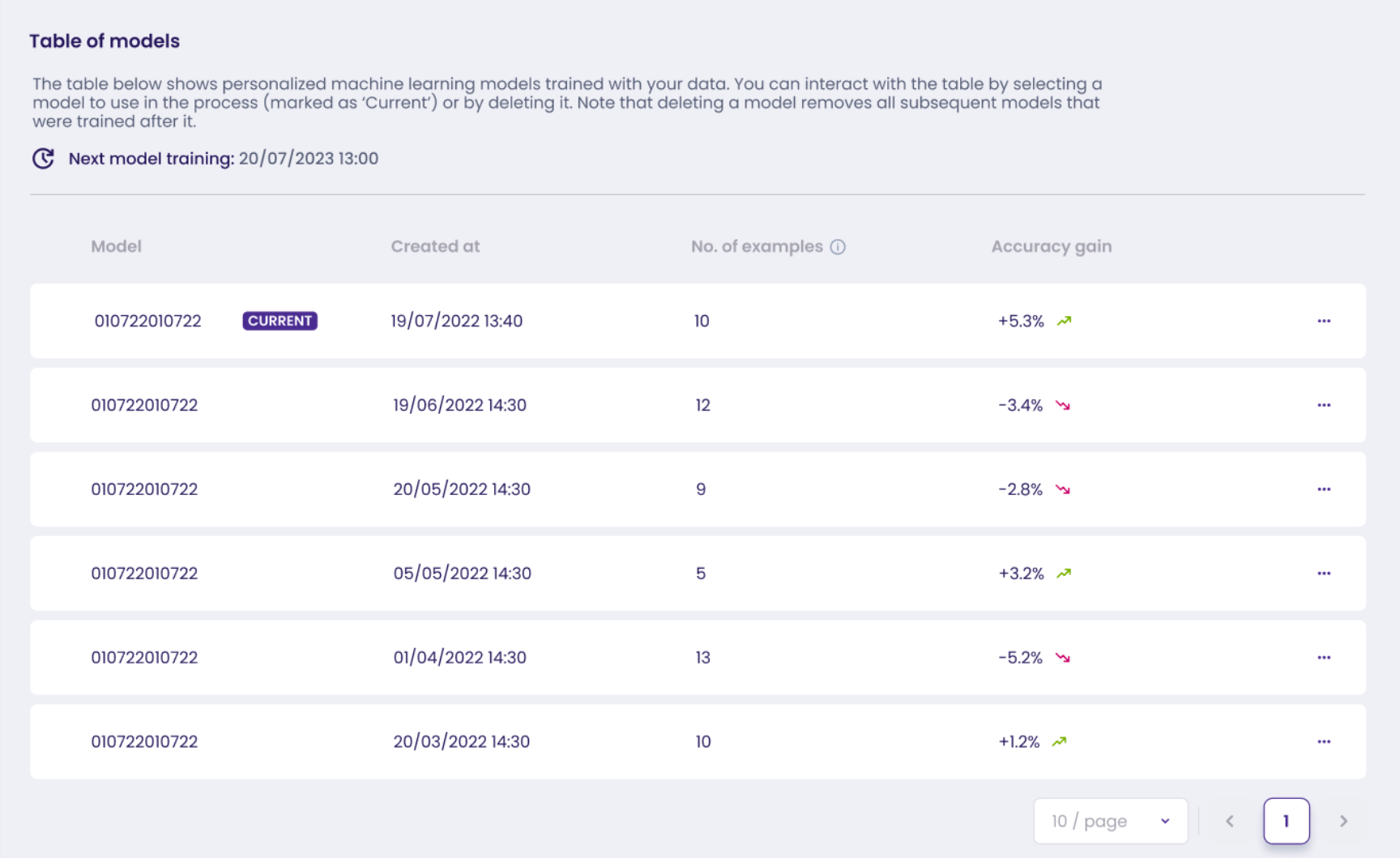
Scrolling down, you will see the **models table** - it will help you track all of the training updates.
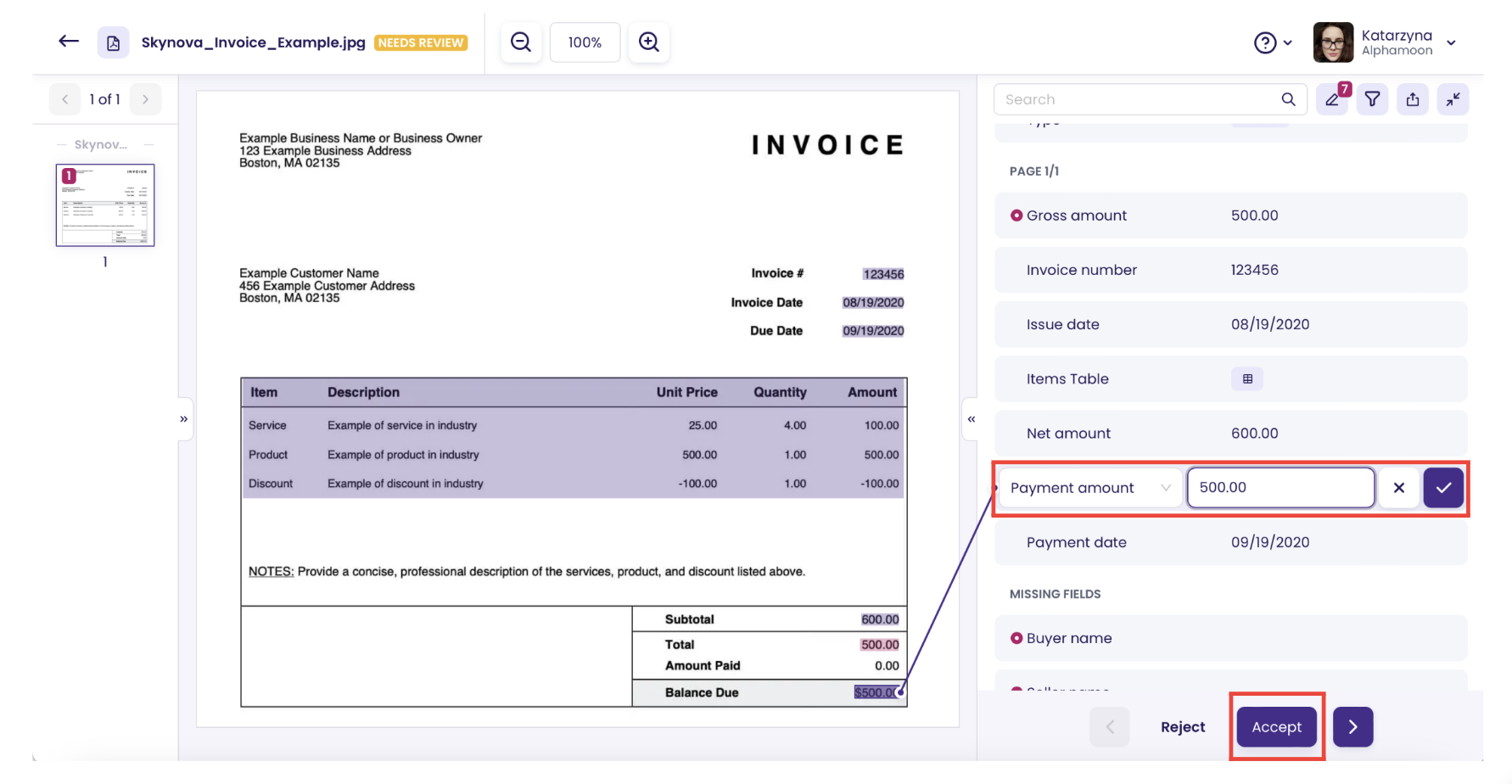
In order to create a new model all you need to do is enter the Supervision view, and make corrections to the data extracted from your documents. The number of documents with corrections depends on the training option you have chosen and its parameters.
Accept corrections
In the models table you can check when each model was created, how many examples it has (accepted collections) as well as the accuracy gain showing the overall training progress.
{% hint style="info" %}
If you will make multiple corrections in one collection, we will count them as one in the Continuous Learning feature.
{% endhint %}
Models table
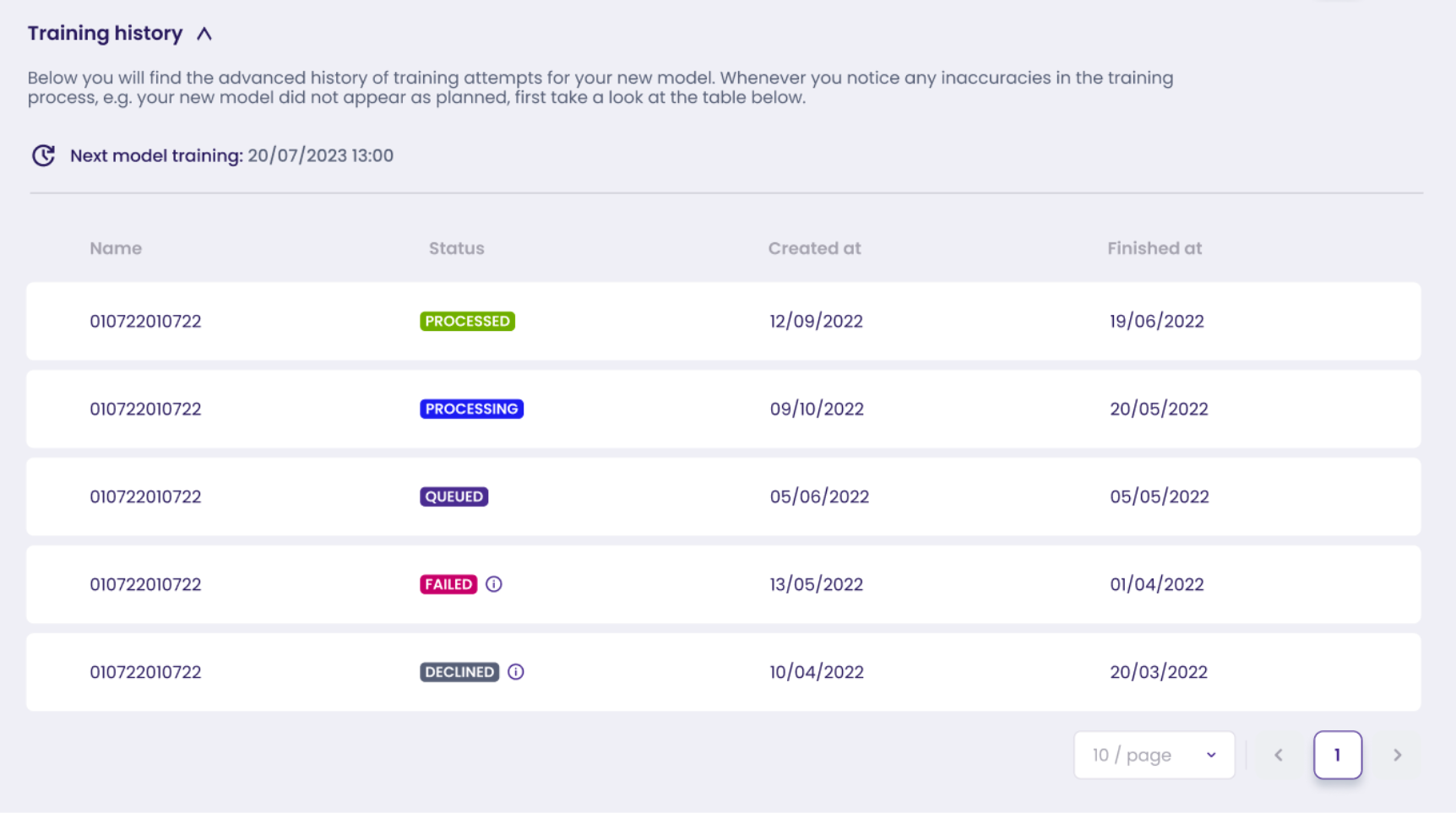
Below the models table you will the **history of model training attempts** showing training statuses, dates of creation as well as the date when model training has finished.
Every time your new model did not appear in the model table or you will see any other inaccuracies in the training process we recommend you to check this table first.
Training history
{% hint style="success" %}
**Congrats!**
Now you now how to use our Continuous Learning feature. Next - [Document Splitting](https://alphamoon.gitbook.io/documentation/~/changes/E5WHATIwrsF0u91xTwvD/features/document-splitting).
{% endhint %}
#### See next: